

When in 2011 Austrian student and activist Max Schrems first asked Facebook for the data that the social network stored about him, he received a CD containing 1,200 pages of data. Now – partly thanks to the GDPR – this process is much smoother. It only takes a few minutes and a few clicks for you to know what the internet giants know about you. For this blog, we placed a data request with Facebook and Google. We documented the process and its outcome below.
Requesting data from Facebook
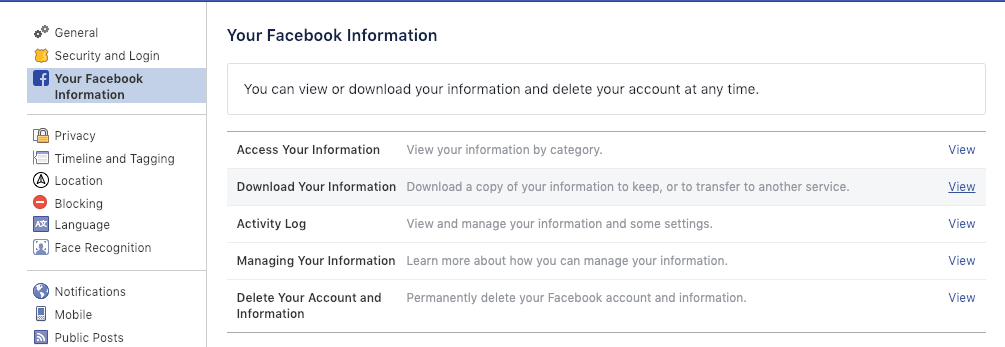
In Facebook’s main menu, click on the arrow icon. Then go to Settings and Your Facebook Information. Under Download Your Information, choose what you want to get, and in what quality and format. We ticked everything, in high quality and in HTML format (JSON is an alternative).
About 20 minutes later, we could download a 2GB archive, containing a total of 24 folders with HTML files full of specific information. The first folder about_you contains data related to the way in which Facebook recognizes your face on photographs. Then there is a mini-file called the “lifestage description” of your friends, with only one information, referring most probably to the fact that me and most of my friends are about thirty years old – Starting adult life.
The file your_address_books gave us the biggest surprise. It contains several hundred names of my contacts, complete with their telephone numbers. However, it is not exactly the group of my Friends on Facebook (even though there is an intersection), but generally the contacts from my mobile phone.
The list begins with a numerous batch characterized by the same date of adding in 2015, which most probably refers to the moment when I copied my contacts to my new phone or allowed Facebook to access them.
Another folder contains all statuses written by me on my or someone else’s wall, sorted chronologically. At the very top, there is a photograph from last weekend, while at the bottom there is probably my historically first status from autumn 2008! The similar applies to Comments and Likes.
In addition to a simple list of friends, the Friends section contains also friend request files.
Those files surprised me with a list of 247 names (I had to copy them to an Excel sheet to count them all) of people, who, over the decade of my Facebook existence, sent me a friend request which I ignored. Similarly, the archive contains a file with all Events (sorted by whether I pushed the Attending button or not).
location_history is an interesting and quite detailed folder, containing information on my (rather my mobile phone’s) on-line location since August last year. Each day is usually related to dozens of data items, with precision to hundred-thousandths of degrees of latitude and longitude. For instance, my visit to Hamburg was recorded in the following format:
August 4, 2018 19:27 (53.54649, 9.96586)
Facebook makes money from advertising, and that’s why I wondered what the ads folder would contain.
The advertisers_you’ve_interacted_with file has a history of only a month and something. In that period, I clicked on a dozen of ads, according to Facebook. I can remember most of them and the rest that I can’t remember seems plausible.
In the ads_interests file, I’ve found 408 keywords that, according to Facebook, should represent “your interests based on your activities on Facebook and other actions, which help us show you the most relevant ads.” Here Facebook reminds you of something that is not widely known: the fact it can follow users on websites other than Facebook.
Now what does this all mean?
How can Facebook evaluate this data? The keywords ranged from the very general and broad ones (Current events, Music, Life) to proper names (Häagen-Dazs, Lionel Messi, South Park). Some of the keywords on the lists remain a mystery to me.
I had to google Marvin Gaye, John Tewksbury or Alvin Kraenzlein (adding more data to those that Google stores about me in the process). Despite the fact I found out that the last two were early 20th-century athletes and hurdle race pioneers, I don’t have a clue how they got into my list.
It is clear that Facebook holds a large amount of really in-depth data about me and even if its accuracy may sometimes still be questionable, there is no doubt that it is a treasure-trove for anyone wanting to convert me into a paying customer for their product or service. While some see Facebook’s free service plus the increased relevance of targeted advertising as compensation enough for me to give away my data freely, many people would disagree. My personal data is valuable – and increasingly so – hence I should be able to benefit from it. That’s why VETRI allows users to earn extra income and rewards based on their anonymized personal data, by connecting them directly with advertisers, market researchers and businesses that are interested in their data.
Next week, we will have a closer look at Google and what kind of personal data the company holds about us. Stay tuned!


